打开淘宝,首页内容会给你推荐很多商品,这些商品有的是你曾经浏览过、类似的物品,有些是你可能潜意识里有过的物品,于是你不断的刷着淘宝,不断的点进去看,不断的买买买。打开抖音,首页推荐了很多视频,或许是你的亲人同学同事相关内容,或许是美食旅游帅哥美女搞笑,但都有一个特点,你很感兴趣,你停不下来看的节奏。
打开美团,首页给你推荐了很多美食,单是火锅,就有好吃的、距离你最近的、最便宜的,再到其它的奶茶等等,于是你就不断的查看挑选,最终选择了最心仪的店铺与美食。
打开今日头条,首页同样会给你推荐很多内容,小红书、知乎、腾讯新闻、微博等,似乎它们展示的内容差不多你都感兴趣,好像很懂你的心,最终让你付出了时间、精力、金钱的成本。那么它们背后的推荐系统到底是怎么实现的呢?
推荐系统包含两类,基于人和基于物的推荐。所谓基于人的推荐就是根据用户的历史行为、兴趣爱好推荐,比如在淘宝你最近浏览了Nike的运动鞋,那么再次打开就会给你推荐Nike的运动鞋、阿迪的运动鞋。所谓基于物的推荐就是根据正在浏览商品的推荐,比如你在淘宝正在浏览Nike的运动鞋,划到底部时会给你推荐同款或不同颜色型号的运动鞋。要做推荐系统,除了系统本身之外,有两大不可或缺的因素:海量数据、人工智能算法。
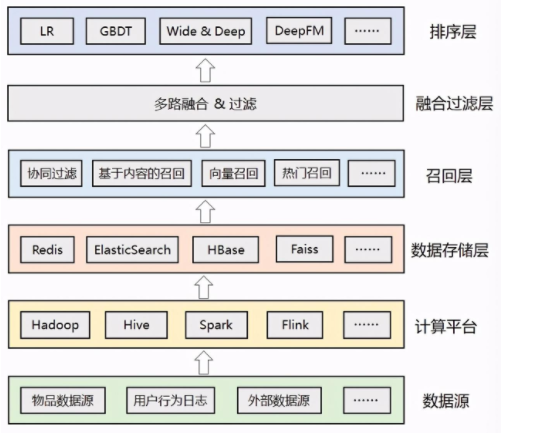
在推荐系统中包含数据排序层、融合过滤层、召回层、数据存储层、计算平台层、数据源,数据排序层则是根据人工智能算法,筛选出更精准的推荐内容给到用户,如LR(Logistic Regression)逻辑回归算法、DeepFM(DeepFactorizationMachine)算法将特征数据组合给到用户;过滤层就是将召回层基于不同规则召回来的数据进行融合过滤,召回层就是通过各种推荐策略,如基于内容将数据获取回来,数据存储层就是将清洗后的用户数据使用Hbase、MongDB等大数据库存储起来,计算平台层就是将底层的各种数据进行清洗加工,使用spark离线计算或flink实时计算处理,数据源就是从日志、数据库中获取物品数据、用户数据、业务数据。
介绍了推荐系统的架构后,我们来看看推荐系统最重要的模块-算法,在推荐系统中有四类算法。
1、基于内容的推荐算法,根据用户的浏览记录、购买记录推荐相似的物品。一般使用逻辑回归算法,将用户的浏览记录和项目的信息、离散特征,通过编码;将数值类特征归一化,或者通过分桶技术,进行离散化;然后通过LR模型进行训练。LR模型很稳定,这种算法很简单但不够智能。
2、基于协同过滤的推荐算法,及将拥有相同经验或相同喜好用户群体的物品互相推荐,比如Alice和Bob都购买了啤酒、尿布,在协调过滤中会认为Alice和Bob是类似的人,在Alice的商品浏览页会推荐Bob曾经浏览过的商品,或者在Bob的商品浏览页会推荐Alice曾经浏览过的商品;
3、混合推荐算法,即将不同的算法混合使用,在不同阶段使用不同的推荐算法,呈现给到用户;
4、基于模型的推荐算法,即将用户特征(比如年龄、性别、地域、消费能力、消费爱好)等和商品的特性作为特征,使用机器学习算法进行训练,预测用户对商品的喜好程度,推荐商品给到用户,甚至作为商业产品卖给广告主,按点击率计费。
在真实业务场景中,要做一个推荐系统还是很有挑战的,首先在数据源部分有结构化、非结构化的数据,需要先将采集的数据做清理之后,才能用于机器模型训练;其次如何权衡算法和性能,生产环境的数据非常之多,非常之复杂,如何在最快的响应时间内推荐给到用户最智能的数据呢?;最后用户的兴趣爱好是不断在变的,具有实时性,使用历史数据进行推荐,不够准确;
又是一年双十一要到了,淘宝、口碑、京东等等各大平台的预售已经开始了,在你打开App准备双十一买买买的时候,也可以思考下这背后的逻辑噢。平时在刷知乎刷小红书刷微博刷抖音的时候。也可以结合今天介绍的知识,巩固加深对业务、算法的理解,做好互联网的搬砖工~